# 8086内存空间分布图

# 8086知识点
# 8086的硬件资源
一个14个寄存器

# 修改段寄存器的值
8086cpu不支持直接将数值送入段寄存器(硬件设计问题).
解决这个问题的套路:
数据 -> 一般的寄存器(ax,bx,cx,dx) -> 段寄存器
# 栈相关操作
8086cpu的指令集 提供了具有栈特性的指令:
- push: 向栈中压入一个字
- pop: 向栈中读取一个字
TIP
- push,pop实质上就是一种内存传送指令,可以在寄存器和内存之间传送数据,类似于mov操作内存单元,与mov指令不同的是, push和pop指令访问的内存单元的地址不是在指令中给出的,而是由ss:sp指出的.
- 执行push和pop指令时, sp的内容自动发生改变.
push指令执行步骤:
TIP
- sp = sp-2;
- 向ss:sp指向的字单元送入数据
pop指令的执行步骤:
TIP
- 从ss:sp执行的字单元中读取数据;
- sp = sp-2;
与栈相关的两个寄存器
- ss: 堆栈段,保存堆栈段的地址.
- sp: 堆栈的栈顶指针.
在使用push 和 pop命令之前,我们需要设计好堆栈段的地址以及堆栈的栈底的位置, 这决定了堆栈的大小, 而且我们需要知道的是栈的出栈和入栈是以字为单位的,在8086中字是16位,即2个字节,所以我们需要程序员自己需要保证堆栈段的大小是2字节的倍数, 8086在硬件上没有提供越界的检查, 所以当我们使用push或者pop时, 会有可能出现超过段范围的现象, 需要我们程序员自己编程时注意.
没有所谓的栈底指针,需要我们自己记住自己约定的栈段的栈底.
TIP
- 堆栈段大小由ss寄存器和sp寄存器,来决定
- 堆栈段的大小应该是字的整数倍
- cpu没有提供硬件的越界检查,需要自己注意
例子1: 设置一个起始地址为0x10000H,大小为8个字(16个字节)的栈
!设置ss和ip
mov ax,1000
mov ss,ax
mov sp,0010
例子2: 利用栈的特性,交换ax,bx寄存器的值,栈的大小为2个字
!设置ss和ip
mov ax,1000
mov ss,ax
mov sp,04
mov ax,1234
mov bx,4321
push ax
push bx
pop ax
pop bx
# 用汇编语言编写源程序
# 编写汇编代码: 程序中的三种伪指令
实例代码:
assume cs:codesg
codesg segment
mov ax,0123H
mov bx,0123H
add bx,ax
;模板代码,将控制权还给dos操作系统
mov ax,4c00h
int 21h
codesg ends
end
段定义:
TIP
- 一个汇编程序是由多个段组成,这些段用来存代码,数据,或者栈空间
- 一个有意义的汇编程序至少要有一个代码段.
- 定义程序的段: 每一个段需要有段名
段名 segment --段的开始 .... 段名 ends --段的结束
告诉汇编器,汇编程序结束: end
TIP
汇编程序的结束标记,如程序结尾处不加end,编译器在编译程序时,无法知道程序在哪里结束.
假设: assume: 指明哪一个段, 存放到哪一个段寄存器
TIP
含义是假设某一段寄存器和程序中的某一个用 segment ... ends 定义的段相关联 --assume cs:codesg 指将cs寄存器和名字叫做codesg的段关联, 猜测是, 汇编器, 会帮我们设置cs的值, 为代码段的位置.
# 汇编和链接
当我们将汇编代码写好后, 使用 MSAM.EXE 将代码汇编成目标文件(.obj) 之后通过 链接程序(LINK.EXE), 将目标文件链接成可执行exe文件
msam 汇编程序.s
link 汇编程序.obj
汇编器执行过程产生的文件:
TIP
- 目标文件(*.OBJ)是我们对一个源程序进行编译要得到的最终结果.
- 列表文件(*.LST)是编译器将源程序编译为目标文件的过程中产生的中间结果.
- 交叉引用文件(*.CRF)同列表文件一样,是编译器将源程序编译为目标文件过程中产生的中间结果.
- 对源程序的编译结束,编译器输出的最后两行告诉我们这个源程序没有警告错误和必须要改正的错误.
链接器执行过程产生的文件:

# 汇编指令
# 指令表
# mov
移动值
mov 目的(寄存器),源(立即数|源寄存器|[ds段内的偏移值])
- 目的寄存器: ax(ah,al),bx,cx,dx
- 立即数: 0x0123
- 源寄存器: ax(ah,al),bx,cx,dx
- 内存单元地址:[ax|bx|cx|dx], ds:ax
注意不能直接这么写:
mov ax,[2]
# jmp
无条件跳转到指定的代码段和ip偏移地址
!跳转段和ip(端内偏移)
jmp [段地址:]偏移地址
!只跳转ip(端内偏移)
jmp 偏移地址
! 直接跳转到通用寄存器中的地址(只改变ip)
jmp ax|bx|cx|dx
# inc
自增1
inc ax
# loop
功能: 实现循环(计数型循环)
格式: loop 标号
cpu 执行loop指令时要进行的操作
- (cx)=(cx)-1
- 判断cx中的值: cx == 0 ? 向下执行 : 跳转到标号位置执行.
要求:
- cx中要提前存放循环次数,因为(cx)影响着loop指令的执行结果.
- 要定义一个标号 例子:
- 计算2^10次方
assume cs:codesg
mov ax,2
mov cx,9
s: add ax,ax
loop s
codesg segment
codesg ends
end
WARNING
- 上面的写法类似于c语言的 do{...}while(), 会先执行一次
- 注意cx计算器的值是 循环前先减1,之后再判断是否为0, 当(cx)=1时,已经不满足循环条件
- 计算ffff:006字节单元中的数乘以3,结果存储在dx中
assume cs:codesg
codesg segment
mov ax,ffffh
mov ds,ax
mov ax,[6]
mov cx,2
s: mov ax,ax
loop s
mov dx,ax
mov ah,4ch
int 21h
codesg ends
end
# 汇编程序执行的方式
# 使用debug程序来执行
 在debug中除了可以使用
在debug中除了可以使用 t, 来单步执行, 开可以使用 p 和 g
- 继续命令P(Proceed) :类似T命令,逐条执行指令、显示结果。但遇子程序、中断等时,直接执行,然后显示结果, 类似于idea时调试的跨过(Step Over), t 可以理解为 步进(step Into),会进入到函数内部执行...
- 运行命令G(Go):从指定地址处开始运行程序,直到遇到断点或者程序正常结束。类似于idea的Resume Program (跳到下一个短点处或者结束).
//debug时 g [段地址:偏移地址]
# 在dos中执行

# [...]的规定与(...)的约定
当我们使用[]在mov,add指令是,表示从内存中的数据段进行取值, 是汇编语言的语法的规定.
而我们经常用()来描述汇编指令,使我们更容易理解
- [...] (汇编语法规定)表示一个内存单元
![img]()
- (...) (为学习方便做出的约定),表示一个内存单元或寄存器中的内容.
![img]()
TIP
例子: (ax)=0010H, 意思是ax寄存器的内容是0010H


# 其他约定
# 符号idata表示常量
例子:
mov ax,[idata]
mov bx,idata
mov ds,idata
# 汇编例子
# 从内存中读取数据
要求: cpu要读取一个内存单元,必须要给出这个单元的内存地址
原理: 在8086pc中,内存地址由段地址和偏移地址组成(段地址:偏移地址)
解决方案: DS和[address]配合
DS是数据段, 当我们使用[地址]时,默认会从ds段获取数据.
将10000H中的数据读取到al中,读取一个字节
mov bx,1000H
mov ds,bx
!从1000:0开始读取一个字(8086为16位,2个字节), 而al只有8位,则丢弃其他的字节
mov al,[0]
将10000H中的数据写到10000H的内存单元.写一个字节
mov bx,1000H
mov ds,bx
mov [0],al
读一个字,将内存中10000H的字形数据送入寄存器ax
mov bx,1000H
mov ds,bx
mov ax,[0]
写一个字,将寄存器ax的值送入 内存中10000H
mov bx,1000H
mov ds,bx
mov [0],ax
值得注意的是,因为硬件不支持直接把数据送入段寄存器,我们需要先将数据送入通用寄存器,之后再通过通用寄存器送给段寄存器
# dos模拟器使用
# 调试程序 debug
命令:
- d: 以二进制显示内存单元的值
d [段地址:偏移地址] - e: 以二进制的方式修改内存单元的值
将10000H设置为11,10001H设置为22...
e 1000:0 11 22 33 44 - r: 显示各个寄存器的值
- u: 以汇编语言的方式解释内存单元的数据
u [段地址:偏移地址] - a: 以汇编指令的方式,修改内存单元的值
a [段地址:偏移地址] - r: 修改各个寄存器的值,包括ip和cs
#修改ip的值 rip - t: 单步执行, cs:ip 所执行的代码
# 字节序
x86架构为小端模式, 即地位数据保存在低地址, 而高位数据保存在高地址.

# 字传送
向数据段传送一个字/字节的数据, 从数据段中获取一个字/字节的数据

# 8086提供的栈机制

push命令, 会进行 sp = sp -2. 也就是说栈是低地址方向生长. push命令一次必须放入一个字,即16位
ss 寄存器保存的是栈段的段地址, sp栈顶指针寄存器, 存放栈顶的偏移地址. 任意时刻: ss:sp指向的永远是栈顶.
因为 sp 的值 已知会在 0000-FFFF之间, 当溢出时也会回到对应的值.
栈操作是危险的, 因为我们给栈分配的空间, 可能仅仅只是8字节,, 我们不断的pop和push都是有可能超界.
想象一下, 通常来说一个程序的内存分配, 依次是代码段, 数据段, 栈段(段的位置完全由汇编程序员自己指定.这里只是一种广泛的方式), 如果通过push指令,不断入栈, 就可能覆盖掉我们的数据段甚至代码段的数据.
如果我们不断的pop,导致超界, 就可能覆盖掉下一个程序的代码段数据.

我们可以通过指定cs, ds, ss,分别指定代码段,数据段,栈段的位置. 实际上, cs,ds,ss的取值也可以相同, 都使用一个段.

# 引入段前缀: 一个异常现象的对策.
 发现在汇编源代码文件中编写, 类似于
发现在汇编源代码文件中编写, 类似于mov ax,[0]的指令时, 通过编译后, 发现.obj文件里是mov ax,0 与我们的想法不同. 为了解决这个问题. 需要显示的添加段前缀, mov ax, ds:[0], 此时编译后才是mov ax, [0]. 猜测是masm汇编器的问题.
# 段前缀的使用.
看下面两个代码:

这两个代码的作用都是将内存中ffff:0~到ffff:b 共计12个字节的数据拷贝到0:200~020b的内存单元中.
初始方案是不断的切换数据段基值, 从ffff切换到0020,然后借助一个bx来作为索引. 这种方式需要不断的切换段基值.
而方案2, 则是使用了附加段寄存器(ES), 让ES段指向0020, 同时通过段前缀es:[bx],来指定内存单元.
这里想要说明的问题是, 并不是只有ds数据段才能只使用[],而是说,默认情况下,如果不使用段前缀,那么[]默认指的就是数据段, 我们可以通过段前缀符之指定[]对应的段.
# 定义字数据
dw: 定义字 db: 定义字节 dd: 定义双字
我们可以通过 dw,db,dd来定义数据. 下面有一个案例:
 在这段代码中, 一共有8个字的数据,占用了16字节的空间, 并且是从代码段的开始地址开始存储的.
但是这段代码存在问题: 当运行这个程序时,ip为0, 这会导致计算机上我们的数据识别成了指令, 会导致出错. 为了解决这个问题, 我们可以通过
在这段代码中, 一共有8个字的数据,占用了16字节的空间, 并且是从代码段的开始地址开始存储的.
但是这段代码存在问题: 当运行这个程序时,ip为0, 这会导致计算机上我们的数据识别成了指令, 会导致出错. 为了解决这个问题, 我们可以通过end关键字,来指定一个标号, 作用就是运行程序时,会将ip设置为标号所在的内存地址.

通过end 指定'start'标号为ip的位置, 我们将start标号,放置在实际上代码的位置.
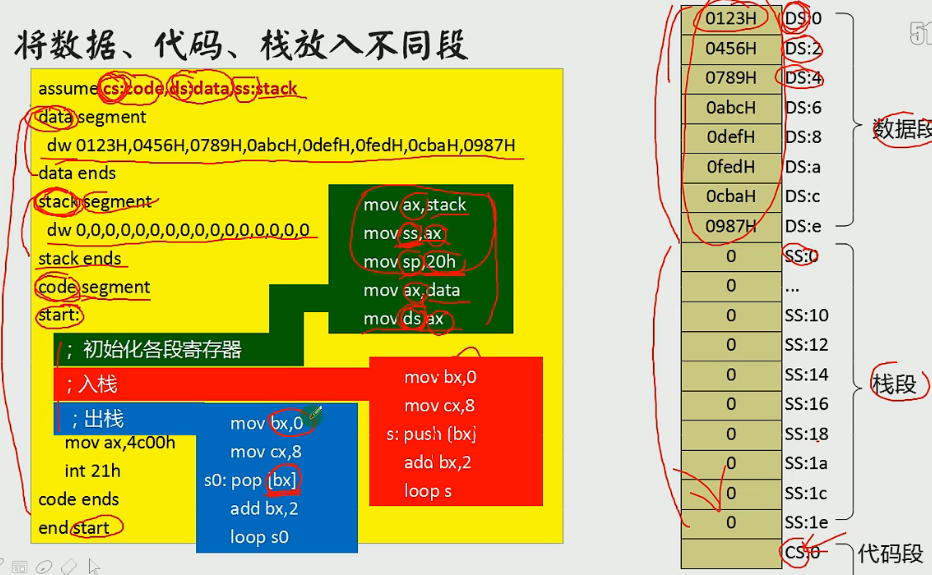
# 将数据,代码和栈放入不同的段的编程方式.
讲过各种数据按照类别放入对应的段,可以使代码更加清晰, 适合编写大型程序.
当我们引入数据段,代码段,栈段后, 我们的代码步骤中就需要首先初始化各段的寄存器. img
讲过调试发现mov ax,stack执行时,stack的值变成了某个具体的值, 这表明,如果我们通过assume来设置段, 系统就会帮我们动态分配各个段的位置,然后将我们段名换成具体的地址.
# 处理字符问题.
 当我们将 字符使用引号包围时, 汇编器认为它是一个字符类型数据,实际上会将的ASCII码值放置到对应的位置, 也就是时候凡是字符的的方法,机会替换为数值.
当我们将 字符使用引号包围时, 汇编器认为它是一个字符类型数据,实际上会将的ASCII码值放置到对应的位置, 也就是时候凡是字符的的方法,机会替换为数值.
小写字符与大写字符的规律: 小写字符的从低位到高位算,第6位为1,而大写字符第6位为0, 除此之外其他位都相等,所以小写字符比大写字符大32. 正好是20H.
# 大小写转化案例

学习两个新的指令, and和or, 也就是与和或指令. 我们知道小写字符的第6位为1, 那么转为大写, 我们只需要将让它与一个第6位为0,其他位为1的数字进行与运算, 这样不管字母的第6为是几,都是被置为0,从而实现了转大写.
大写字符转小写字符同理, 只要将第6为置为1,其他位为0, 然后进行或运算.这样第6位就变成了1, 使大写字符变为了小写字符.
# [bx+idata]的寻址方式

也就是说,我们可以给bx添加一个偏移地址,这里的思想其实就是C语言的数组.
这个段是数据段,但是存储了多个数组的数据时, 这个偏移地址就是数组的起始地址.
比如说有一个案例: 有两个相同大小的字符数组,不过一个数组起始地址为0, 另一个是5. 现在要求经过5次循环,同时对两个数组进行操作. 第一个数组大写转小写, 第二个数组小写转大写.
# si和di寄存器

# [bx+si]和[bx+di]方式指定地址.

# bx+si+idata和[bx+di+idata]的方式指定地址

# 内存的寻址方式总结

# 二重循环问题
错误的案例程序:

TIP
在上面的案例中, 想要实现二重循环, 但是发现里层循环会直接覆盖掉外层循环的cx值. 那么如何实现一个二重循环呢? 既然原因是外出循环的cx值被覆盖, 那么我们只需要将其被覆盖前保存到除了cx的一个地方即可, 当里层循环结束时, 再从改地方取出放入到
几种实现方案:
- 将cx暂存到另一个寄存器(不推荐, 占用一个寄存器, 寄存器资源紧张)
- 将cx保存到指定的内存单元(不推荐,需要明文指定某个单元, 多重循环需要,指定多个内存单元)
- 将cx通过push和pop保存到栈中(推荐, 多重循环也只需要push即可.)
# 用于内存寻址的寄存器用法
- bx和bp指针, 都是基值寄存器,当我们使用
[bx|bp]时,一个默认指定是ds段,一个默认指的是ss段. 我们可以通过指定段前缀符,来显示的指定是哪一个段. - 只有bx,bp,si,di 可以写到
[]里面,其他寄存器都不可以.

# 指令要处理的数据有多长?
在一些指令中, 因为包含寄存器的原因, 因此可以推断出处理的数据有多长, 比如说: mov [0],bx, 将bx中1个字大小的数据存储在数据段0开始的内存单元, 但是如果说指令是这样呢: mov [0],1, 因为1是一个10进制数, 我们不知道1是一个字节大小,还是一个字大小. 所以我们需要通过word ptr或者byte ptr去指定操作数据的大小

# 操作结构化的数据

# div 除法指令

div 后面只跟上一个操作数. 因为被除数是默认在 ax寄存器或者 dx+ax的. 当div 后面跟上的是一个8位的寄存器或者8位的存储单元(需要使用byte ptr显示的指定), 则商的结果保存在Al寄存器, 余数的结果会保存在ah寄存器. 也就是说AX寄存器的高八位保存的是余数, 而低八位保存的是商.
当我们进行16位除数的除法时,余数和商一般都是16位的, 此时不可能用一个AX寄存器保存16位的余数和商, 因此组合使用DX寄存器和AX寄存器, DX寄存器保存的是高16位, 而AX寄存器,保存的是低16位. 同时计算出来的商保存在AX中, 而余数保存在DX中
# dup伪指令,实现数据重复
 例子:
例子:

# 流程转移

# 操作符offset
操作符是一个伪指令, 用于获取标号位置的指令的偏移地址

# jmp指令, 无条件转移
 jmp 指令按照转移的距离分为3种:
jmp 指令按照转移的距离分为3种:
- 段内短转移:
jmp short 标号, ip的修改范围是-128~127,8位的位移 - 段内近转移
jmp near ptr 标号, ip的修改范围是-32768-32767, 16位的转移. - 段间转移(远转移):
jmp 2000:1000
# jmp指令, 转移地址在指令中(立即数)
jmp 指令近转移和短转移运作原理: jmp指令中, 近转移和短转移是根据当前指令的地址,相对于跳转的地址的位移而跳转的.
TIP
在其他包含立即数的指令中, 指令中会包含原本的立即数的值, 然而对于jmp指令中跳转地址的这个立即数,却是一个相对值, 一个相对于当前指令地址的值.
比如说:
 虽然指令上显示的是
虽然指令上显示的是JMP 000A, 但是对应的机器码的值是EB05, 并不是EB0A.
当机器取出JMP 000A 这个双字节指令之后,ip的值为05(jmp指令地址为03,双字节指令,取出后ip+2, 所以是05), 而将当前的ip值加上EB05中的05后,就正好是0A,即我们想要跳转到地址.
jmp 指令远转移
jmp指令,远转移写法:
jmp far ptr 标号
TIP
指令中存储的不是位移了, 直接就是目标地址的立即数.
# jmp指令,转移地址在寄存器中
此时寄存器总的值是多少,就跳转到ip值为寄存器值的地方.

# jmp指令, 转移地址在内存中.

# 总结

# jcxz指令(条件转移)
 jcxz 后面是立即数时, 机器码里面也是位移值. loop指令也是位移
jcxz 后面是立即数时, 机器码里面也是位移值. loop指令也是位移
# 根据位移进行"相对"转移的意义
为什么要使用相对的位移值,进行位移呢?

# call 指令

# call near ptr 标号
本质:
- 将下一条指令地址, 压入栈中.
- 将ip值进行修改.
进行的是一个近转移(16位的位移)
# call far ptr 标号 实现的是段间转移

# call 转移地址在寄存器

# call 转移地址在内存中

# 返回指令 ret和retf

# call 指令和 ret 指令配合使用
通过call指令和ret指令配合使用可以实现子程序.
sub1: add ax,ax
ret
sub1 是这个子程序的入口地址, 执行完毕后通过ret返回.
使用call命令和ret命令时需要注意一些问题:
TIP
- 使用call和ret指令前, 一定在汇编程序中声明栈段, 并且初始化栈段, 确保我们使用的内存空间是合法的内存空间, 以避免程序偶尔执行正确,偶尔失败的现象.
- call 指令会将下一条指令地址,入栈, 在子程序中执行涉及到栈操作时, 确保执行ret时, 栈顶是正确的返回地址.
# mul 乘法指令

# 子程序编程,将参数保存到栈中
 一个案例:
一个案例:
 其中,
其中, ret 4 含义就是在执行ret后, 将sp = sp + 4, 即pop两个字.
TIP
参数保存有三种方案:
- 保存到寄存器
- 保存到数据段的某个内存单元
- 保存到栈中.
# 寄存器冲突问题的解决

一个合格的子程序,不应该破坏外界程序的寄存器状态. 调用前是什么样,调用后也应该是什么样.
例子:

# 标志寄存器

# 哪些指令的结果会影响标志寄存器?

# of标志位

# ADC 带进位的加法指令

# ADC指令应用: 大数相加(32位,64位数)

# 128位数相加

# SBB指令(带借位的减法指令)

# cmp(比较)指令

# cmp 实现无符号数大小比较

# cmp 实现有符号数大小比较

# 条件转移指令

# 条件转移指令的使用

# DF标志和串传送指令

# rep指令(重复指令)
TIP
重复执行cx次, rep后面跟着的指令. 通常与串指令搭配使用.
TIP
当我们需要拷贝大量的内存数据到指定的内存位置时, 如果使用si和di的话, 每次复制完,还需要手动的让si++和di++.
因此我们使用串操作指令movsb(mov string byte) 和 movsw (mov string word),
- 它默认以
ds:si作为源地址,以es:di为目标地址. - 它会以
DF(Direction Flag)方向标志,决定指令执行完毕, si和di是递增还是递减. 也就是决定了方向, 可以实现从低地址复制到高地址, 或者从高地址复制到低地址. movsb一次复制一个字节, si和di 一次变化1movsw一次复制一个字,si和di,一次变化2- 通过
cld和std指令, 设置DF寄存器的值,分别设置为0(clear)和1(setup), 为0时si和di加1, 为1时,si和di减1
# 移位指令(逻辑,循环,算术,带进位的左右移)

- 逻辑左移: 将最高位移动到CF寄存,低位补0
- 逻辑右移: 将最低位移动到CF寄存,高位补0
- 循环左移: 将最高位移动到CF寄存和最低位
- 循环右移: 将最低位移动到CF寄存和最高位
- 算术左移: 将最高位移动到CF寄存,最低位补0 (和逻辑左移效果相同)
- 算术右移: 将最低位移动到CF寄存,最高位为原本最高位的值(是1则补1,是0补0)
- 带进位循环左移: 先将CF原本的值(是否进位)移动到最低位,然后将最高位移动到CF.
- 带进位循环右移: 将CF的值移动到最高位, 然后最低位移动到CF.
TIP
- 移动位数大于1时, 必须使用一个寄存器来存储移动位数, 也就是说只有立即数为1时, 才支持使用立即数作为移动位数.
- 无符号数,可以使用逻辑移动实现, 乘2和除2, 而有符号数应该使用算术移动来实现乘2和除2
例子:

# 显示原理
 .
.
内存空间是对, 所有存储功能的设备统一编址 8086cpu的内存空间为1MB, 其中A0000到BFFFF为显存空间.
在第B8000h-BFFFFh 共32k空间是80*25彩色字符模式,第0页的显示缓存区.
这里就是实际要显示在显示器上的内容.
# 显示缓冲区的结构

# 例子: 屏幕中间显示

# 数据标号

当数据标号去掉了冒号:后, 不仅代表着地址, 还代表着长度.
比如说 a db 16 dup(0), a后面跟着的是db,这会使我们在使用mov指令时, 默认认为它是一个字节mov b,2->mov byte ptr cs:[8],2
例子:

将标号保存为数据:

可以实现"指针的指针"的效果
# 代码的直接地址表
借助数据标号, 我们可以将多个子程序的地址,作为数据,保存在一张表中.通过索引来获取每个子程序的起始地址.

# 中断

# 单步中断
 CPU提供了单步中断功能, 实现调试功能. debug中的-t命令就是使用了单步中断功能, 会执行中断处理程序.
CPU提供了单步中断功能, 实现调试功能. debug中的-t命令就是使用了单步中断功能, 会执行中断处理程序.
指的注意的是, 单步中断会设置 TF,IF为0, 使其它的中断处理程序不会执行.
# 案例1: 中断不响应的现象.
 某些指令执行完毕后,会设置IF=0,关闭中断, 不会响应中断.
当我们给栈段寄存器赋值时就会出现这个问题. 比如说
某些指令执行完毕后,会设置IF=0,关闭中断, 不会响应中断.
当我们给栈段寄存器赋值时就会出现这个问题. 比如说mov sp, ax, 它会设置IF=0, 目的就是为了让我们下一条指令设置sp的值时, 不会收到其他中断的干扰(操作了栈).
也就是说 修改ss和sp操作应该是一个原子性的操作, 设置了栈段寄存器通常也需要修改栈顶指针寄存器, 设置栈的大小. 因此当我们修改栈段寄存器后, 就应该设置栈顶指针, 利用上IF=0这个时机. 因为执行一条指令(大部分的指令)后, IF会恢复为1
# 中断程序示例1

TIP
当int指令被执行时, 自动会执行三条指令(中断隐指令)
pushf
push cs
push ip
在中断程序中, 返回应该用iret, 也会自动执行三条隐指令
pop ip
pop cs
popf
# 中断程序示例2
 中断程序的常规步骤
中断程序的常规步骤
TIP
- 保存用到的寄存器
- 处理冲段
- 恢复用到的寄存器
- 使用
iret返回
# BIOS中断和DOS中断
 BIOS提供的中断历程,并没有全部占用256个, 而DOS系统选择扩展了中断向量表.
BIOS提供的中断历程,并没有全部占用256个, 而DOS系统选择扩展了中断向量表.
# 端口
计算机系统中, 将外设和内存分开编址, 比如说在8086中,端口的命名空间大小是(65536)64k, 即最大支持65536个端口, 因为8086在寻址端口时只有16根地址线. 实际上一个IO设备会占用多个端口.
# 主板上的CMOS RAM芯片介绍
CMOS RAM芯片是一个易失性的芯片, 通常需要一个纽扣电池,来维持里面的数据信息. 该芯片包含一个系统时钟和系统硬件的配置信息(Configuration Info):
TIP
系统配置信息可以包括以下内容,这里给出一些例子:
1.启动顺序(Boot Order):指定系统启动时检查的设备顺序,例如硬盘、光驱、USB设备等。
2.硬盘设置(Hard Drive Configuration):包括硬盘的参数和设置,如硬盘容量、接口类型(如IDE、SATA)、磁盘模式(如AHCI、RAID)等。
3.内存设置(Memory Configuration):涉及系统内存的配置,包括内存容量、内存频率、内存时序等。
4.电源管理(Power Management):包括系统的节能和电源管理设置,如睡眠模式、待机模式、唤醒事件等。
5.实时时钟(Real-Time Clock):保存当前的日期和时间,用于系统的时间管理。
6.键盘设置(Keyboard Configuration):包括键盘类型(如PS/2、USB)、键盘布局(如QWERTY、AZERTY)等。
7.显示器设置(Display Configuration):涉及显示器的设置,如分辨率、刷新率、颜色设置等。
8.引导加载程序(Bootloader):保存引导加载程序的配置信息,如GRUB、Windows Boot Manager等。
9.硬件监控(Hardware Monitoring):包括温度、风扇转速、电压等硬件监测信息。
10.USB设置(USB Configuration):涉及USB接口的设置,如USB Legacy支持、USB端口开关等。
# CMOS RAM 芯片的一些问题.
因为CMOS RAM芯片保存的是一些系统的配置信息, 而没有这个信息则会导致BIOS读取不到硬件配置信息而无法开机.
CMOS RAM芯片是一个易失性的芯片, 当纽扣没有电时, 里面的数据就会丢失. 而厂商也提供了解决方法:
TIP
可以通过在主板上找到一个称为"CMOS清除"或"CMOS重置"的跳线或按钮来完成。通过按下或移动该跳线或按钮,可以将CMOS RAM中的配置参数恢复为默认设置。请注意,进行CMOS重置将清除所有用户自定义的设置,包括日期、时间、启动顺序等。
这个默认配置的数据,固化在芯片内部的.
这也是当用户自己修改了某些硬件配置参数导致无法正常开机后的解决方案. 比如修改了内存的电压,想要进行超频, 结果无法开机了.
- 第一次开机时,CMOS RAM芯片保存的信息通常与实际的硬件不符,能否正常开机?
TIP
计算机系统通常会在第一次启动时进行一次称为"CMOS重置"或"默认设置"的过程。在这个过程中,系统会将CMOS RAM中的配置参数恢复为预定义的默认值。
默认值通常是由计算机制造商预先设置的,以适应大多数硬件配置。这样,在第一次启动时,即使CMOS RAM中的数据与实际硬件不匹配,系统也能够使用默认值进行启动。
一旦系统成功启动,用户可以进入BIOS设置界面,手动修改CMOS RAM中的配置参数,以使其与实际硬件配置相匹配。在BIOS设置界面中,用户可以更改启动顺序、硬盘设置、内存设置、电源管理等参数,以满足其特定需求。 :::
# 8086通过IO命令向端口读写数据.
 端口读写指令示例:
端口读写指令示例:

# 读写CMOS RAM芯片

# 硬件外中断
外中断分为可屏蔽中断和不可屏蔽中断.

- 其中可屏蔽中断中为什么要将IF和TF标志位设置为0?
TIP
因为当执行完一条指令后,需要处理中断请求(前提此时IF为1), 那么如何从众多IO设备中选出一个优先级最高的IO请求?, 是通过物理的接线来实现的,接线越靠前的中断请求会屏蔽后面的, 于是CPU只能接收到优先级最高的中断设备的IO请求.
为什么要将IF和TF标志位清空(置为0), 是为了当前这个高优先级的中断请求,被其他的中断请求再次打断(已经选出了一个要执行的中断请求了, 结果那些竞争失败的中断请求,想要再次尝试竞争).
需要等当前中断程序处理完成或者说这个中断程序执行过程中自己开中断(IF=1),允许别的中断打扰.
可屏蔽中断,是CPU可以决定是否处理的中断. 而不可屏蔽中断,CPU执行完当前指令后,就必须去执行,该中断不受到flag标志寄存器影响.
# 外中断处理过程

# 硬件中断与软件中断的区别
硬件中断由硬件主动去触发,调用硬件中断处理程序. 而软件中断, 是我们在编写软件时,主动去调用的中断.
以int 9号硬件中断举例, 这个中断是当用户按下按键时,自动回去执行的程序, 目的是去接受按下的键的扫描码,然后查表获取对应的字符, 然后放入到键盘缓冲区.
而int 16号中断是软中断. 我们编写软件时,能够主动通过这个中断从键盘缓冲区中获取一个字符, 如果键盘缓冲区为空,则会产生阻塞,等待键盘的输入.

这两种中断处理程序都是存储在BIOS中的, 9号中断处理程序里面本质上是使用了大量的in/out指令,也就是从端口中读写. 这是从硬件中获取数据的一种方式. 还有一种方式就是, 硬件自动将数据与内存空间的某片区域映射在一起, 当读写这个空间时,就是读取了硬件的数据, 这也是硬件实现的。
这两种方式也就是IO设备统一编址和独立编制
8086对于IO设备采用统一编址. 但是我认为显卡是一个特例, 因为显存映射到了内存空间. 我们可以直接通过操作这个空间的单元来操作显存.
# PC机键盘处理过程
- 键盘输入
![img]() 键盘上每一个按键相当于一个开关. 多个按键近似于一个矩阵. 有一个扫描器.逐行扫描. 根据开关的状态,来判断哪些按键按下, 哪些按键松开.
键盘上每一个按键相当于一个开关. 多个按键近似于一个矩阵. 有一个扫描器.逐行扫描. 根据开关的状态,来判断哪些按键按下, 哪些按键松开.
 键盘上每一个按键相当于一个开关. 多个按键近似于一个矩阵. 有一个扫描器.逐行扫描. 根据开关的状态,来判断哪些按键按下, 哪些按键松开.
键盘上每一个按键相当于一个开关. 多个按键近似于一个矩阵. 有一个扫描器.逐行扫描. 根据开关的状态,来判断哪些按键按下, 哪些按键松开.当按键按下时, 就会产生一个扫描码. 因为是按下产生的码, 因此是通码.
当松开时,也会产生一个码, 是断码.
扫描码的大小是一个字节. 最高位为1时为断码, 最高位为0时为通码.
如下是扫描码表格(似乎不同国家的键盘,扫描码不同, 不如说美式键盘和英式键盘.):

扫描码的类型:
扫描码可以分为三类, 字符键,控制键,切换键.
2. 引发9号中断
 对于字符扫描码的输入,会被加入到内存中的键盘缓冲区存储. 一个输入使用一个字保存, 高位字节保存扫描码, 低位字节保存字符码.
对于字符扫描码的输入,会被加入到内存中的键盘缓冲区存储. 一个输入使用一个字保存, 高位字节保存扫描码, 低位字节保存字符码.
而对于 控制键和切换键, 则使用内存中一个内存单元, 叫做键盘状态字节. 里面的每一个位标识着,控制键和切换键的状态. 比如说大小写锁定键按下, 对应的内存单元的指定bit位变为1.
- 执行int 9中断例程
![img]()

{kind=link}
# 16号中断与9号中断
# 自定义中断程序并且永久安装
在这个案例中, 将9号中断程序进行增强, 然后替代了原本的9号中断程序.
安装程序主要流程如下:
- 初始化用到的段寄存器
- 安装新的程序(将自己的9号中断程序,保存到其他程序不会使用的地方)
- 将原本的中断的地址保存到一个地方(代码段,数据段),通常直接就是自己的代码段
- 修改中断向量表,为自己的中断程序
- 程序返回
- 开始编写自己的中断例程
# 问题记录
- 汇编中数值不能以字母开头,比如
mov ax,efefH会报错, 需要加上一个0,mov ax, 0efefH - 在定义标号时, 不要选择一些特殊的关键字, 比如说
in,out,经测试使用in作为标号会报错. - 在汇编语言中,编译后, 数值默认为10进制,如果想要表达这个数值是16进制,后面需要加上H
- debug, 默认会将数据段放入在076C这个基值, 而075A这个基值100H带大小的空间是debug要占用的.
- mov 指令不会改变指令寄存器的值, 有时候为了重置进位标志, 可以通过
sub ax,ax,去改变